This is how I personally use MC for eBooks and eComics. The steps I have laid out can be tweaked to fit most peoples needs.
Enable data support if not already done:
Go to Tools-->Options-->General-->Features and check Data Support
Setup MC to import desired file types:
In the JRiver installation directory (C:\Program Files (x86)\J River\Media Center 19\Data\) find the folder called default resources.
In this folder find the file called FileAssociations.
Make a new folder beside the default resources folder called "Custom Resources"
Copy the FileAssociations file into that folder.
Open the fileassociation file with notepad and edit the data line so it contains the extensions you want.
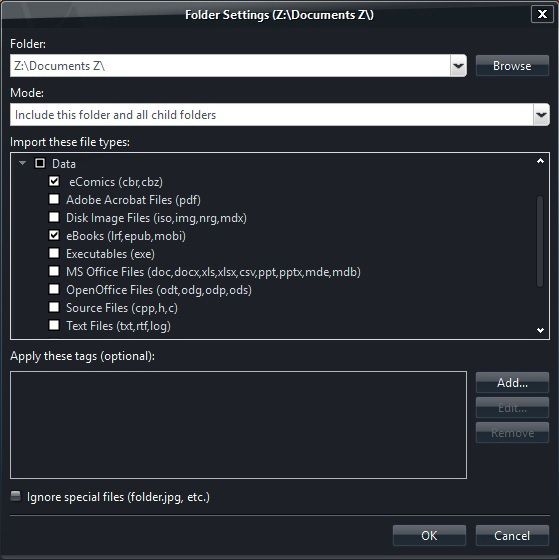
This is what I add to the data line: eComics (cbr,cbz);eBooks (lrf,epub,mobi)
Here is the unedited data line:
<Data>MS Office Files (doc,docx,xls,xlsx,csv,ppt,pptx,mde,mdb);OpenOffice Files (odt,odg,odp,ods);Adobe Acrobat Files (pdf);Text Files (txt,rtf,log);Source Files (cpp,h,c);Webpage Files (html,htm,mht,url);Executables (exe);Disk Image Files (iso,img,nrg,mdx);</Data>Here is the edited data line:
<Data>eComics (cbr,cbz);eBooks (lrf,epub,mobi);MS Office Files (doc,docx,xls,xlsx,csv,ppt,pptx,mde,mdb);OpenOffice Files (odt,odg,odp,ods);Adobe Acrobat Files (pdf);Text Files (txt,rtf,log);Source Files (cpp,h,c);Webpage Files (html,htm,mht,url);Executables (exe);Disk Image Files (iso,img,nrg,mdx);</Data>MC needs restarted for changes to show up.
When done you will see new file types in auto import like below.
Tag fields:
I view eComics and eBooks together in the same views.
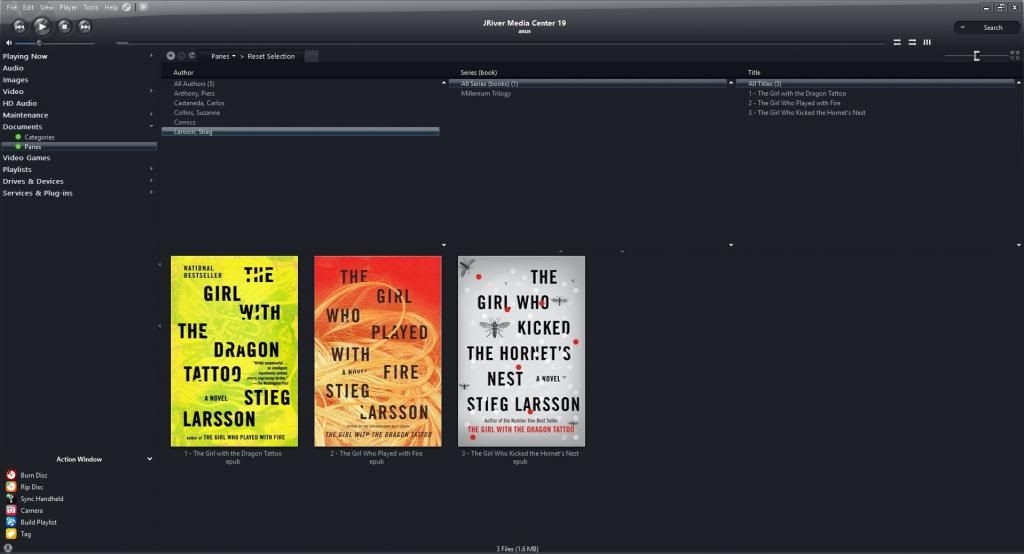
I view by Author-->Series (book)-->Title
All three fields are data type lists (as opposed to String).
Reason being that books can have multiple artists and comics can have multiple series and names because of crossovers.
MC has a field called Series but it is not a list, hence the field called Series (book).
Author is an existing field but Series (book) and Title need to be created.
To do so go to Tools-->Options-->Library & Folders-->Features and select Manage Library Fields
Select Add New Field
Name it Series (book)
Set flags to Data
Set Data Type to List
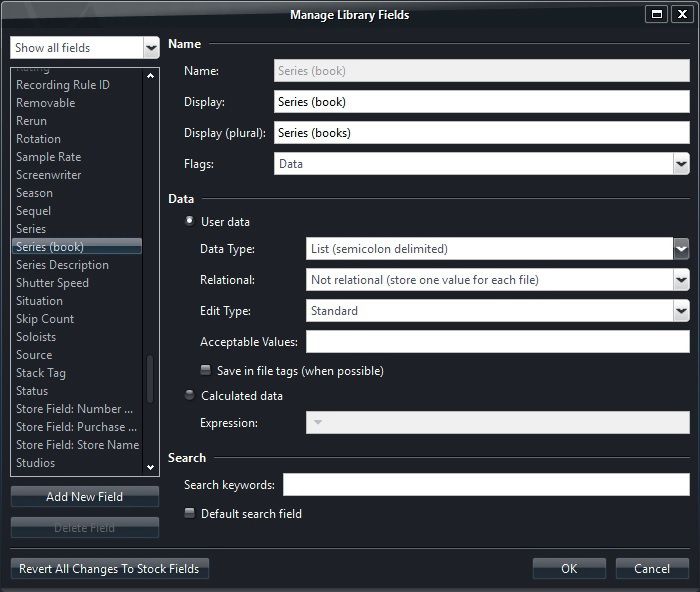
Do the same thing for Title.
Naming conventions and Tag On Import:
Field values are parsed from the filenames on import using Tag On Import.
To make this simple, all files should have a common folder structure.
I use Documents\Author\Series (book)\Title
Examples:
Z:\Documents Z\Documents\Larsson, Stieg\Millenium Trilogy\1 - The Girl with the Dragon Tattoo.epub
Z:\Documents Z\Documents\Larsson, Stieg\Millenium Trilogy\2 - The Girl Who Played with Fire.epub
Z:\Documents Z\Documents\Larsson, Stieg\Millenium Trilogy\3 - The Girl Who Kicked the Hornet's Nest.pdf
Z:\Documents Z\Documents\Castaneda, Carlos\Don Juan\1971 - Separate Reality.pdf
Z:\Documents Z\Documents\Castaneda, Carlos\Don Juan\1972 - Journey to Ixtlan.pdf
Z:\Documents Z\Documents\Anthony, Piers\- No Series\Alien Plot.lrf
Z:\Documents Z\Documents\Comics\Uncanny X-Men Vol 1\Uncanny X-Men Vol 1 303.cbz
Z:\Documents Z\Documents\Comics\Uncanny X-Men Vol 1; Fatal Attractions\Uncanny X-Men Vol 1 304; Fatal Attractions 003.cbz
Z:\Documents Z\Documents\Comics\Uncanny X-Men Vol 1\Uncanny X-Men Vol 1 305.cbz
Note that when a book is not part of a series I put it in a folder called - No Series to keep folder structure consistant.
All comics have Comics in the Author field.
If I want Books to be sorted in a particular order I put a date or series number in the name.
If a field has multiple values, separate them with a semicolon.
Add the following three expression to tag on import:
Author = regex([Filename],/#\\Documents\\(.+?)\\(.+?)\\(.+?)\.#/,1)
Series (book) = regex([Filename],/#\\Documents\\(.+?)\\(.+?)\\(.+?)\.#/,2)
Title = regex([Filename],/#\\Documents\\(.+?)\\(.+?)\\(.+?)\.#/,3)
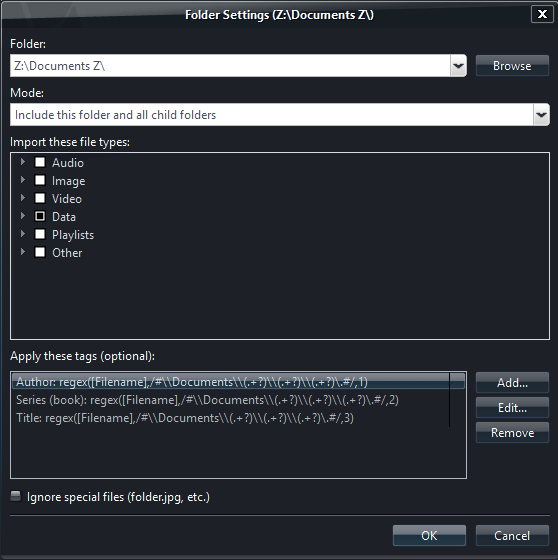
The expressions get the filename info that is contained between the folder called Documents and . for the file extension.
Views:
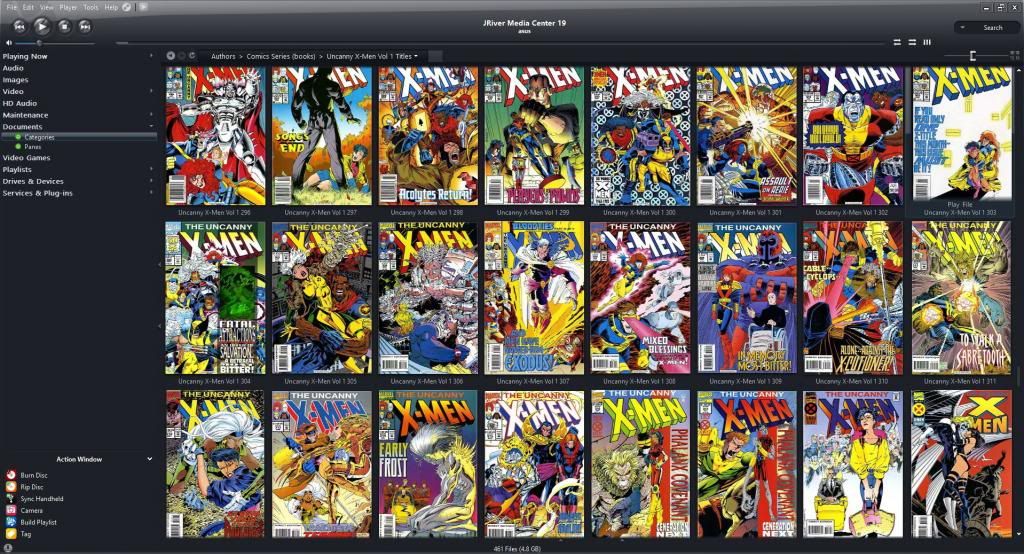
I use a pane view and a category view which are basically setup the same: Author-->Series (book)-->Title
In customize view I make a rule that filename contains \Documents\ and sort by Title (a-z).
I use thumbnails with thumbnail text as follows:
Replace([Title],;,/ as well as)
[File Type]
Cover art sits beside each file and is named the same as the file it is for.
It wont show up in MC by default. To get it to show up:
- Select all the documents in MC
- Change Media sub type to video (in the tag window)
- right click files and choose cover art-->quick find in cover art directory
- change media sub type back to data
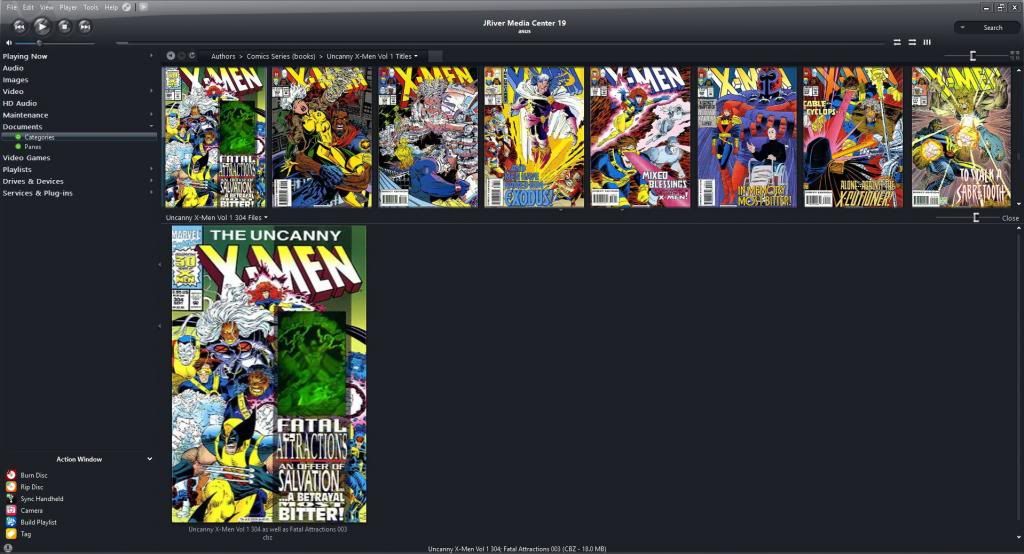
Covers for comics can be obtained by:
Make a copy of the Comic.
Change the extention to rar or zip.
Extract rar or zip to folder.
The first jpg in the folder will be the cover.
Covers for Books can be found by doing a google image search and setting size to large.
I add site:amazon.com to the search.
External programs for reading eBooks:
For Books on a PC I use Calibres ebook-viewer.exe NOT the full calibre program.
It can be found in Calibress install folder C:\Program Files\Calibre2\ .
For comics on a PC and Android I use Comicrack.
For books on android I use Aldiko, FBReader, and ezPDF Reader.
I don't know anything about kindles, Kobos, Nooks, etc.
Additional notes:
Some eBook and eComic formats support embedded metadata.
I have no idea what file types or software support it.
I personally dont have a use for them but others may.
Please share if you have some expertise in this area.
Some software uses opf files similar to how MC uses sidecar files.
As far as I know, MC will not read, write, or use these in any way.
I dont care about Publisher, ISBN, Description, Genre, or Date.
The steps I have shown can be adapted for people who do.
MC has a lot of tools that make naming and organizing large numbers of files easy.
Its good to know how to use: Fill properties from filenames and Rename, Move, & Copy Files.
If anyone has information to add to this, please share.


 Author
Topic: Managing eBooks and eComics with MC19 (Read 26074 times)
Author
Topic: Managing eBooks and eComics with MC19 (Read 26074 times)